
- Монолітні додатки і їх проблеми Всі прекрасно знають, що таке монолітне додаток: все ми робили такі...
- Три виміри масштабування
- теорема CAP
- Мікросервісная архітектура
- Microservices & SOA
- Що таке мікросервіси?
- характеристики мікросервісов
- Угруповання по бізнес-завдань (сервіси мають бізнес-сенс)
- Розумні сервіси і прості комунікації
- децентралізоване зберігання
- Автоматизація розгортання та моніторингу
- Design for Failure (Chaos Monkey)
- Як сервіси будуть один з одним взаємодіяти?
- Різні типи мікросервісной архітектури
- Service Discovery
- Server-Side Service Discovery
- Client-Side Service Discovery
- Message Bus
- Message Bus: «за» і «проти»
- Event Driven Architecture - архітектура, керована подіями
- рішення 1
- рішення 2
- Перехід від моноліту до мікросервісам
- Мікросервіси: «за» і «проти»
- Трохи про моніторинг та тестуванні міроксервісной системи
- Маніфест Джеффа Безоса (Amazon CEO)
Монолітні додатки і їх проблеми
Всі прекрасно знають, що таке монолітне додаток: все ми робили такі дво- або тришарові додатки з класичною архітектурою:
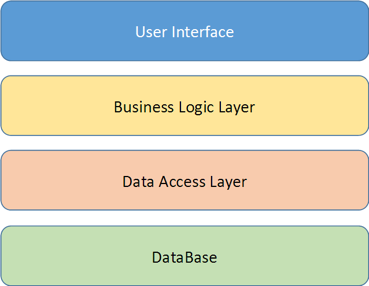
Для маленьких і простих додатків така архітектура працює прекрасно, але, припустимо, ви хочете поліпшити додаток, додаючи в нього нові сервіси і логіку. Можливо, у вас навіть є інший додаток, яке працює з тими ж даними (наприклад, мобільний клієнт), тоді архітектура додатка трохи зміниться:
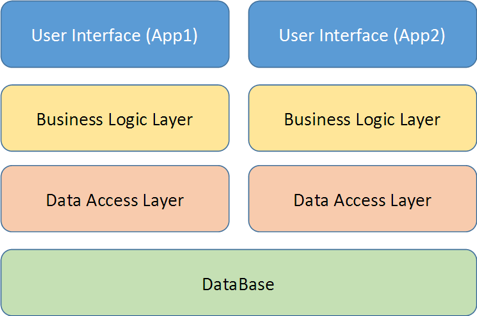
Так чи інакше, у міру зростання і розвитку додатки, ви стикаєтеся з проблемами монолітних архітектур:
- складність системи постійно зростає;
- підтримувати її все складніше і складніше;
- розібратися в ній важко - особливо якщо система переходила з покоління в покоління, логіка забувалася, люди йшли і приходили, а коментарів і тестів немає);
- багато помилок;
- мало тестів - моноліт не розібрати і не протестувати, тому зазвичай є тільки UI-тести, підтримка яких зазвичай займає багато часу;
- дорого вносити зміни;
- застрявання на технологіях (наприклад, я працював в компанії, де з 2003 р технології до сих пір не змінилися).
Рано чи пізно ви розумієте, що вже нічого не можете зробити зі своєю монолітної системою. Замовник, звичайно, розчарований: він не розуміє, чому додавання найпростішої функції вимагає декількох тижнів розробки, а потім стабілізації, тестування і т. Д. Напевно багато хто знайомий з цими проблемами.
розвиток системи
Припустимо, що ви якимось чином змогли уникнути вищезазначених проблем і все ще справляєтеся зі своєю системою, але ж вам напевно потрібно розвивати і масштабувати її, особливо якщо вона приносить в компанію серйозні гроші. Як це зробити?
Три виміри масштабування
У книзі "The Art of Scalability" є поняття «куб масштабування» (scale cube) - з книги "The Art of Scalability". З цього кубу ми бачимо, що існує три ортогональних способи збільшення продуктивності програми: sharding, mirrorring і microservices.
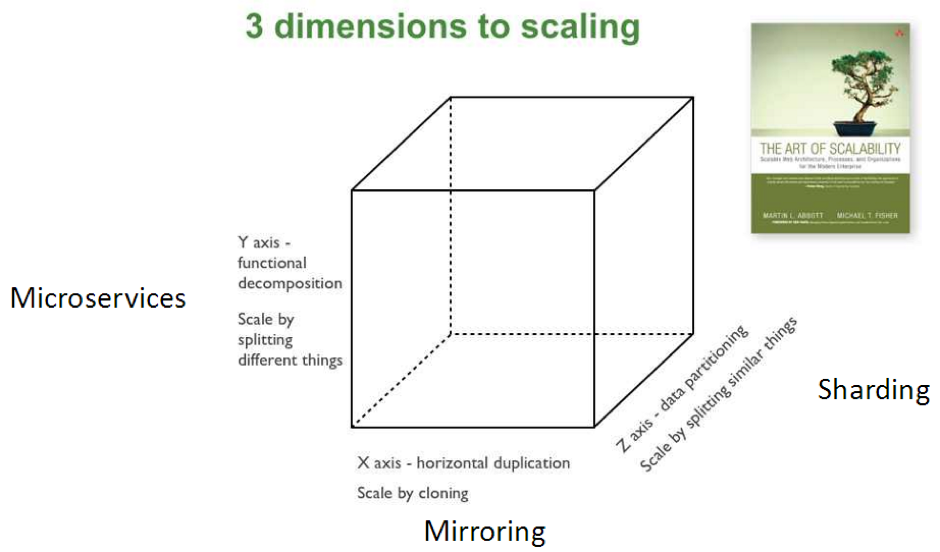
- Sharding ( «шардінг», «розбиття») - розташування однотипних, але різних даних на різних вузлах. Ті, хто працював з NoSQL-базами, знають, що це таке. У вас є ключ шардірованія, за яким ви визначаєте, що у вас, наприклад, дані на А і Б зберігаються на одному вузлі, на В і Г - на іншому вузлі і т. Д. Таким чином, використовуючи інтелектуальний вирівнювач навантаження, ви можете її розподіляти по вашій системі і домогтися більш високої продуктивності.
- Mirroring ( «віддзеркалення») - горизонтальне дублювання або клонування всіх даних, коли ви ставите поруч абсолютно однакові хости. Таким чином ви повністю копіюєте дані. Потрібно це, перш за все, щоб система відповідала на запити з будь-яким очікуваним часом відгуку.
- Microservices (мікросервіси) - ви розбиваєте функціональність по бізнес-завдань. Кожен сервіс буде виконувати певні завдання. Це і є мікросервісний підхід, який ми тут розберемо.
теорема CAP
Взагалі кажучи, якщо ми хочемо розвивати систему, доведеться вирішувати такі питання:
- Як зробити систему доступною з різних регіонів?
- За умови, що система розподілена, як забезпечити узгодженість даних?
- І як при цьому ще й прискорити систему в N раз?
Ці питання приводять нас до CAP-теоремі, сформульованої Брюєром в 2000 р
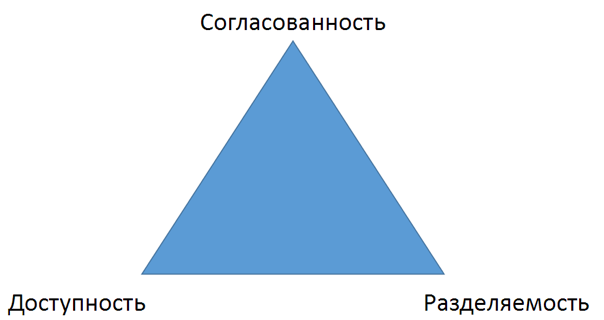
Теорема це полягає в тому, що ви, теоретично, не можете забезпечити системі одночасно і узгодженість (consistency), і доступність (availability), і разделяемость (partitioning). Тому доводиться жертвувати одним з трьох властивостей на користь двох інших. Так само, як при виборі з «швидко, дешево і якісно» доводиться вибирати тільки два варіанти. Тепер розглянемо різні варіанти, які у нас є відповідно до теореми CAP.
CA - consistency + availability
При такому розкладі дані у всіх вузлах у нас узгоджені і доступні. Доступність тут означає, що ви гарантуєте відгук за передбачуване час. Це час не обов'язково маленьке (це може бути хвилина або більше), але ми це гарантуємо. На жаль, при цьому ми жертвуємо поділом на секції - не можемо розгорнути 300 таких хостів і розподілити всіх користувачів за цими хостів. Так працювати система не буде, бо не буде узгодженості транзакцій.
Яскравий приклад CA - ACID-транзакції, присутні в класичних монолітах.
CP - consistency + partitioning
Наступний варіант - коли дані у всіх вузлах узгоджені і розподілені на незалежні секції. При цьому ми готові пожертвувати часом, який потрібен на узгодження всіх транзакцій - відгук буде дуже довгим. Це означає, що, якщо два користувача послідовно будуть запитувати одні й ті ж дані, невідомо, як довго будуть узгоджуватися дані для другого користувача.
Така поведінка характерна для тих монолітів, яким довелося масштабироваться, незважаючи на старовину.
AP - availability + partitioning
Останній варіант - коли система доступна з передбачуваним часом відгуку і розподілена. При цьому нам доведеться відмовитися від цілісності результату - наші дані більше не Консистентне в кожен момент часу, і серед них з'являються застарілі (від мікросекунд до днів). Але, насправді, ми завжди оперуємо старими даними. Навіть якщо у вас трехзвенная монолітна архітектура з веб-додатком, коли веб-сервер віддав вам пакет з тими даними, які ви відобразили для користувача, вони вже застаріли. Адже ви жодним чином не знаєте, чи не прийшов в цей момент хтось інший і не поміняв ці дані. Так що те, що дані у нас узгоджені в кінцевому рахунку (eventually consistent) - нормально. «Узгоджені в кінцевому рахунку» означає, що, якщо на систему перестане впливати зовнішній вплив, вона прийде в узгоджене стан.
Яскравий приклад - класичні DNS-системи, які синхронізуються з затримкою до днів (у всякому разі, раніше).
Тепер, ознайомившись з теорією CAP, ми розуміємо, як можемо розвивати систему так, щоб вона була швидкою, доступною і розподіленої. Та ніяк! Доведеться вибрати тільки два властивості з трьох.
Мікросервісная архітектура
Що ж вибрати? Щоб зробити правильний вибір, потрібно, перш за все, задуматися, навіщо все це потрібно, - необхідно чітко розуміти бізнес-завдання. Адже рішення на користь мікросервісов - дуже відповідальний крок. Справа в тому, що в мікросервісах все значно складніше, ніж зазвичай, т. Ч. Ми можемо зіткнутися з такою ситуацією:
Ось можна просто взяти і розпиляти все на якісь шматки і сказати, що це тепер - мікросервіси. Інакше вам доведеться дуже несолодко.
Microservices & SOA
А тепер поговоримо ще трохи про теорію. Ви всі чудово знаєте, що таке SOA - сервісно-орієнтована архітектура. І тут у вас напевно виникне питання, як же SOA співвідноситься з мікросервісной архітектурою? Адже, здавалося б, SOA - те ж саме, про це не зовсім так. Насправді, мікросервісная архітектура - окремий випадок SOA:
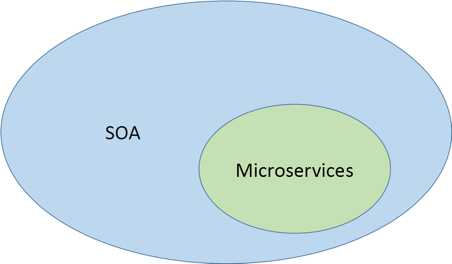
Іншими словами, мікросервісная архітектура - всього лише набір більш строгих правил і угод, як писати все ті ж сервіси SOA.
Що таке мікросервіси?
Це архітектурний шаблон, в якому сервіси:
- маленькі (small),
- сфокусовані (focused),
- слабкозв'язаного (loosely coupled),
- високосогласованние (highly cohesive).
Тепер розберемо ці поняття окремо.
Що значить «маленький» сервіс? Це означає, що сервіс в мікросервісной архітектурі не може розроблятися більше ніж однією командою. Зазвичай одна команда розробляє десь 5 - 6 сервісів. При це кожен сервіс вирішує одну бізнес-завдання, і його здатний зрозуміти один чоловік. Якщо ж не здатний, сервіс пора пиляти. Тому що, якщо одна людина здатна підтримувати всю бізнес-логіку одного сервісу, він побудує дійсно ефективне рішення. Адже буває так, що часто люди, приймаючи рішення в процесі написання коду, просто-напросто не розуміють, що саме роблять - не знають, як поводиться система в цілому. А якщо сервіс маленький, все набагато простіше. Цей підхід, до речі, ми можемо застосовувати окремо, навіть не дотримуючись мікросервісной архітектурі в цілому.
Що значить «сфокусований» сервіс? Це означає, що сервіс вирішує тільки одну бізнес-завдання, і вирішує її добре. Такий сервіс має сенс у відриві від інших сервісів. Іншими словами, ви його можете викласти в інтернет, дописавши security-обгортку, і він буде приносити людям користь.
Що таке «слабо зв'язаної» сервіс? Це коли зміна одного сервісу не вимагає змін в іншому. Ви зв'язані за допомогою інтерфейсів, у вас є рішення через DI і IoC - це зараз стандартна практика, застосовувати яку потрібно обов'язково. Зазвичай розробники знають, чому :)
Що таке «високосогласованний» сервіс? Це означає, що клас або компонент містить всі потрібні методи вирішення поставленого завдання. Однак тут часто виникає питання, чим висока узгодженість (high cohesion) відрізняється від SRP? Припустимо, у нас є клас, який відповідає за управління кухнею. У разі SRP такий клас працює тільки з кухнею і більше ні з чим, але при цьому він може містити не всі методи з управління кухнею. У разі ж високої узгодженості, все методи з управління кухнею містяться тільки в цьому класі, і більше ніде. Це важлива відмінність.
характеристики мікросервісов
- Поділ на компоненти (сервіси).
- Угруповання по бізнес-завдань.
- Сервіси мають бізнес-сенс.
- Розумні сервіси і прості комунікації.
- Децентралізоване управління.
- Децентралізоване управління даними.
- Автоматизація розгортання та моніторингу.
- Design for failure (Chaos Monkey).
Поділ на компоненти (сервіси)
Компоненти бувають двох видів: бібліотеки і сервіси, які взаємодіють через мережу. Мартін Фаулер визначає компоненти як незалежно замінні і незалежно розгортаються. Т. е., Якщо ви можете взяти щось і спокійно замінити на нову версію, - це компонент. А якщо щось пов'язане з іншим і їх незалежно замінити не можна (потрібно враховувати контракти, збірки, версії ...) - вони разом утворюють один компонент. Якщо щось не можна розгорнути незалежно, і потрібно логіка звідкись ще, це теж не компонент.
Угруповання по бізнес-завдань (сервіси мають бізнес-сенс)
Ось стандартна компоновка моноліту:
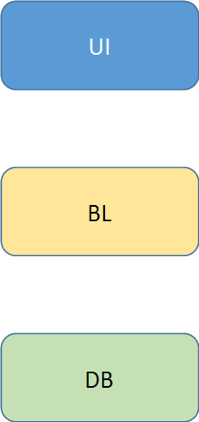
Для підвищення ефективності розробки ви також часто змушені ділити по цим верствам і команди: є команда, яка займається UI, є команда, яка займається ядром, і є команда, яка розбирається в БД.
Якщо ж ви переходите до мікросервісной архітектурі, сервіси та команди діляться по бізнес-завдань:
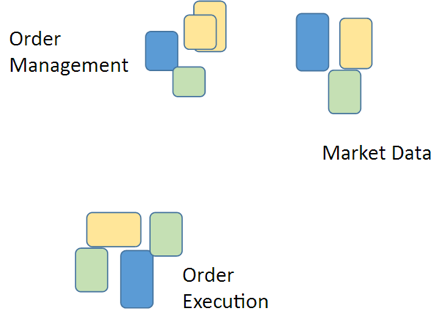
Наприклад, може бути група, яка займається управлінням замовленнями, - вона група може обробляти транзакції, робити по ним звіти і т. Д. Така група буде займатися і відповідними БД, і відповідної логікою, і, може бути, навіть UI. Втім, в моєму досвіді UI розпилювати поки не вдавалося - його доводилося залишати монолітним. Може бути, нам вдасться зробити це в майбутньому, тоді обов'язково розкажіть іншим як ви цього домоглися. Як би там не було, навіть якщо UI залишається монолітним, все одно набагато краще, коли інше розбите на компоненти. Проте, повторюся, дуже важливо розуміти, НАВІЩО ви це робите - інакше одного разу доведеться все переробляти назад.
Розумні сервіси і прості комунікації
Є різні варіанти взаємодії сервісів. Буває, що беруть дуже розумну шину, яка знає і про роутинг, і про бізнес-правила (припустимо, якийсь BizTalk), і до сервісів прилітають вже готові об'єкти. Тоді виходить дуже розумний middleware і дурні endpoint'и. Це, насправді, - антішаблон. Як показав час (на прикладі того ж інтернету), у нас дуже проста і невигадлива середовище передачі даних - їй абсолютно все одно, що ви передаєте, вона нічого не знає про ваш бізнес. Всі мізки ж сидять в сервісах. Це важливо розуміти. Якщо ж ви будете все складати в середу передачі, у вас вийде розумний моноліт і тупі сервіси-обгортки баз даних.
децентралізоване зберігання
З точки зору сервісно-орієнтованих архітектур і, зокрема, мікросервісов, децентралізоване зберігання - дуже важливий момент. Децентралізоване зберігання значить, що кожен сервіс має свою і тільки свою БД. Єдиний випадок, коли різні служби можуть використовувати одне сховище, - якщо ці служби є точними копіями один одного. Бази даних один з одним не взаємодіють:
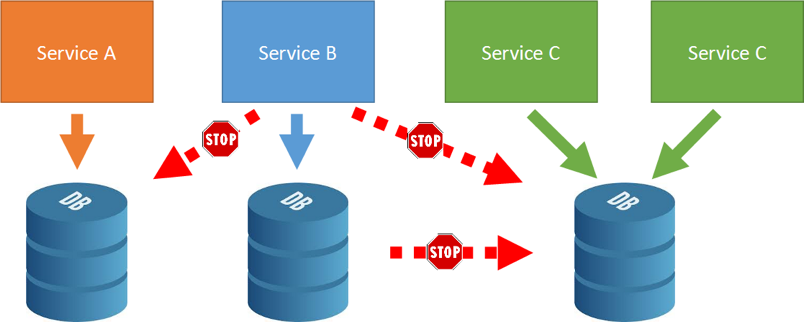
Єдиний варіант взаємодії - мережева взаємодія між сервісами:
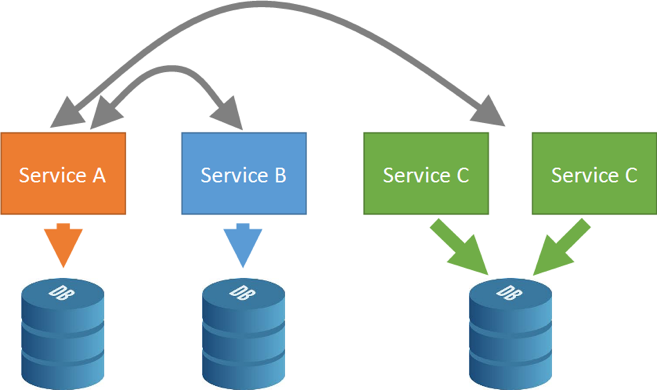
Middleware тут може бути різний - ми про це ще поговоримо. Виявлення сервісів і взаємодія між ними може відбуватися просто безпосередньо, через виклик RPC, а може і через якийсь ESB.
Автоматизація розгортання та моніторингу
Автоматизація розгортання та моніторингу - то, без чого до мікросервісной архітектурі краще навіть не підходити. Т. ч. Ви повинні бути готові в це інвестувати і найняти DevOps-інженера. Вам обов'язково знадобиться автоматичне розгортання, безперервна інтеграція і поставка. Також вам знадобиться безперервний моніторинг, інакше ви просто не зможете встежити за всіма численними сервісами, і все перетвориться в якесь пекло. Тут корисно використовувати всякі корисні штуки, які допомагають централізувати логгірованіе, - їх можна не писати, т. К. Є хороші готові рішення на кшталт ELK або Amazon CloudWatch.
Design for Failure (Chaos Monkey)
З самого першого етапу, починаючи будувати мікросервісную архітектуру, ви повинні виходити з припущення, що ваші послуги не працюють. Іншими словами, ваш сервіс повинен розуміти, що йому можуть не відповісти ніколи, якщо він очікує якихось даних. Таким чином, ви відразу повинні виходити з ситуації, що щось у вас може не працювати.
Наприклад, для цього компанія Netflix розробила Chaos Monkey - інструмент, який ламає сервіси, хаотично їх вимикає і рве з'єднання. Цей потрібно, щоб оцінити надійність системи.
Як сервіси будуть один з одним взаємодіяти?
Візьмемо приклад простого додатка. Картинки, наведені нижче, я взяв з блогу Кріса Річардсона на NGINX - там детально розповідається, що таке мікросервіси.
Отже, припустимо, у нас є якийсь клієнт (необов'язково навіть UI-ний), який, щоб надати комусь потрібні дані, взаємодіє з сукупністю інших сервісів.
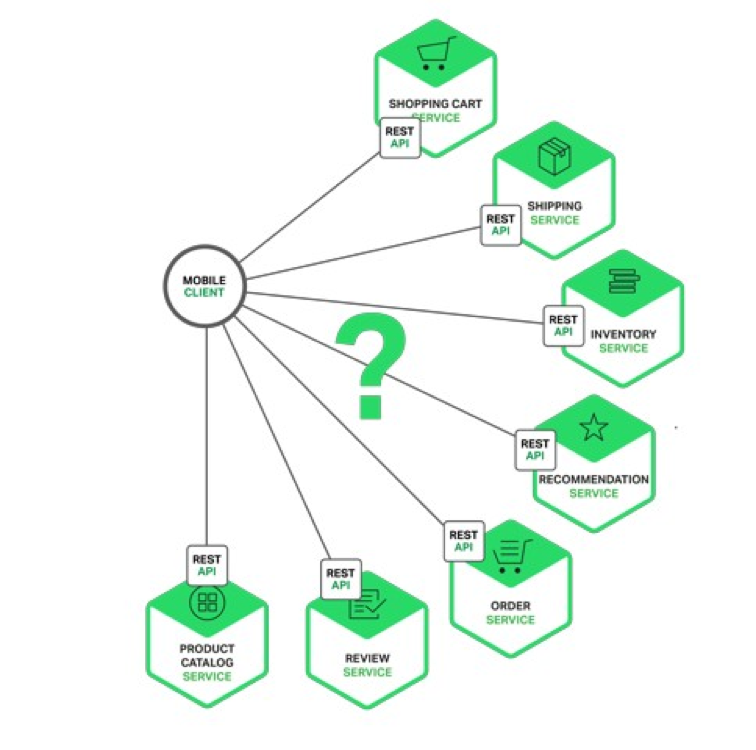
Здавалося б, все просто - клієнт може звертатися до всіх цих сервісів. Але на ділі це виливається в те, що конфігурація клієнта стає дуже великою. Тому існує дуже простий шаблон API Gateway:
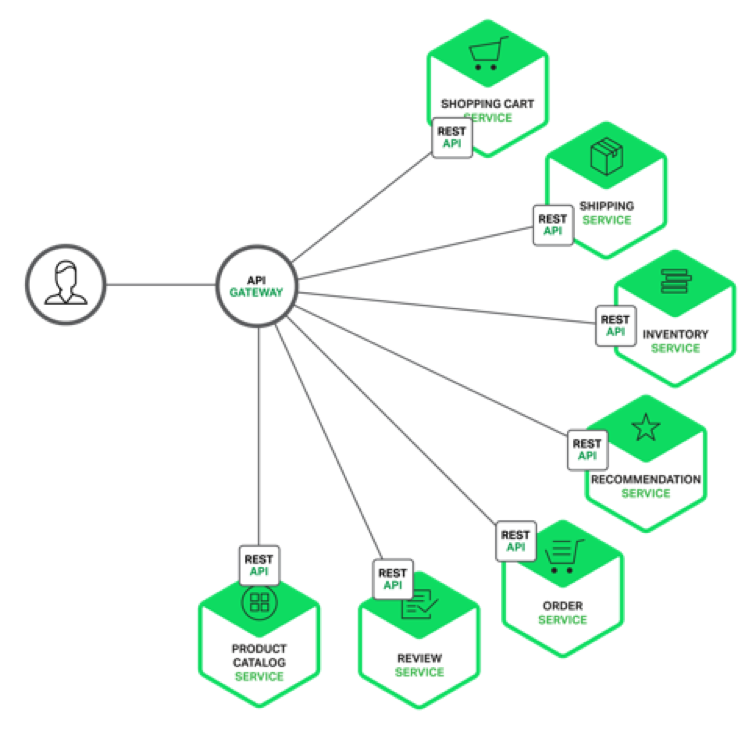
API Gateway - перше, що потрібно розглядати, коли ви робите мікросервісную архітектуру. Якщо у вас в бекенд кілька сервісів, поставте перед ними найпростіший сервіс, завдання якого - збирати бізнес-виклики до цільових сервісів. Тоді ви зможете здійснювати маппинг транспорту (транспорт буде не обов'язково REST API, як на картинці, а яким завгодно). API Gateway надає дані в тому вигляді, в якому вони потрібні конкретно саме цього типу користувачів. Наприклад, якщо буде веб-і мобільний додаток, у вас буде два API Gateway, які будуть збирати дані з сервісів і надавати їх трохи по-різному. API Gateway не повинен ні в якому разі містити ніякої серйозної бізнес-логіки, інакше б ця логіка всюди дублювалася, і її складно було б підтримувати. API Gateway тільки передає дані, і все.
Різні типи мікросервісной архітектури
Отже, припустимо, у нас є UI, API Gateway і десяток сервісів за ним, але цього мало - так нормальне додаток не побудуєш. Адже зазвичай сервіси якось взаємопов'язані. Я бачу три способи зв'язати сервіси:
- Service Discovery (RPC Style) - сервіси знають один про одного і спілкуються безпосередньо.
- Message Bus (Event-driven) - якщо ви використовуєте шаблон «видавець -подпісчік», і ні «передплатник» не знає тих, хто на нього підписаний, ні «видавець» не знає, звідки приходить вміст. Вони зацікавлені тільки в вмісті певного типу - вони підписуються на повідомлення. Це і називається message-driven- або event-driven-архітектура.
- Hybrid - змішаний варіант, коли для одних випадків ми застосовуємо RPC, а для інших - message bus.
Service Discovery
Service Discovery (RPC Style)
Ось найпростіший варіант Service Discovery:
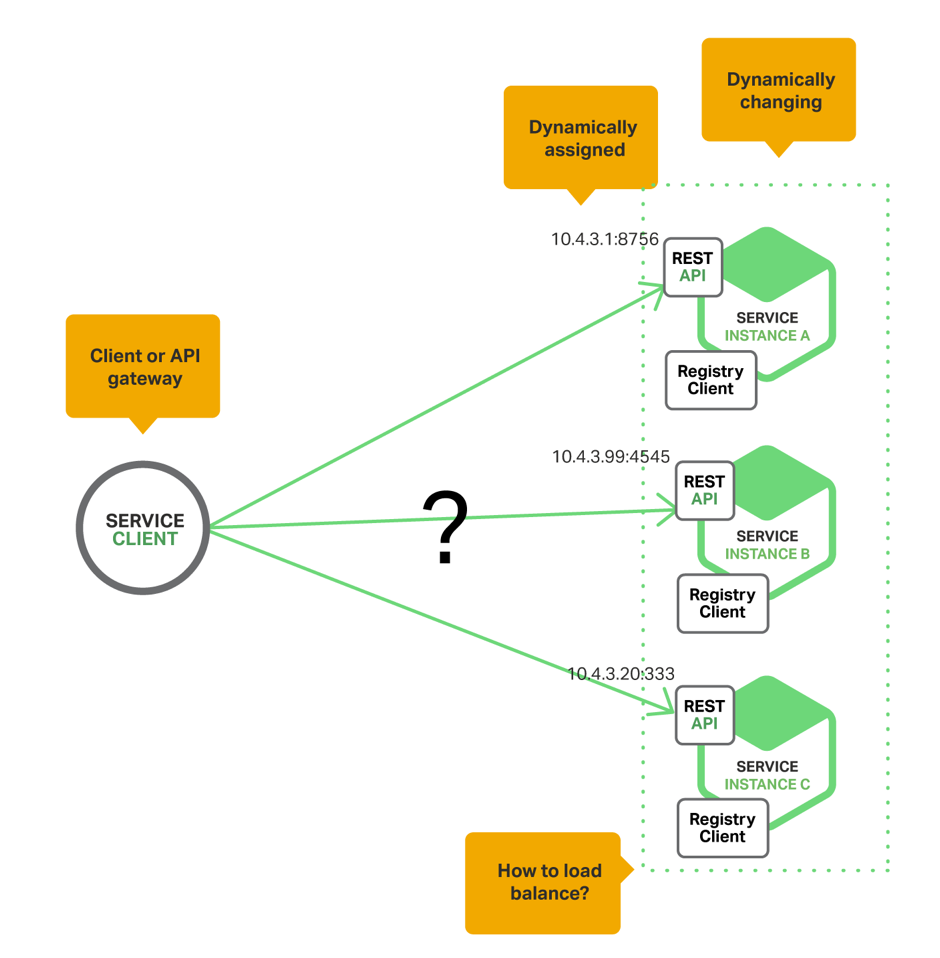
Тут у нас є клієнт, який звертається до різних сервісів. Однак, якщо в конфігурації клієнта буде зашитий адресу конкретного сервісу, ми будемо зв'язані по руках і ногах, адже нам може захотітися розгорнути все заново, або ж може бути ще один екземпляр сервісу. І тут нам допоможе Server-Side Service Discovery.
Server-Side Service Discovery
При Server-Side Service Discovery ваш клієнт взаємодіє не безпосередньо з конкретним сервісом, а з вирівнювачем навантаження (load balancer):
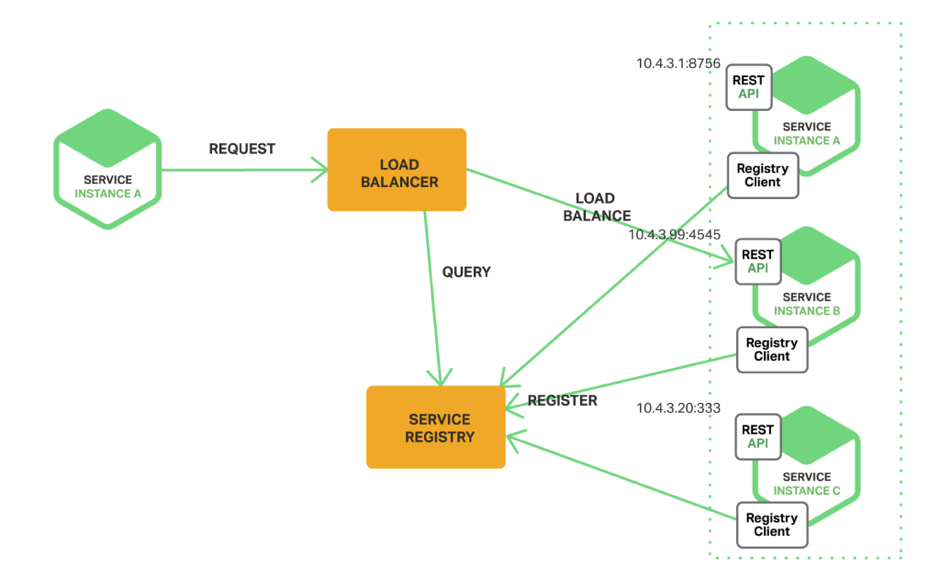
Load balancer існує дуже багато: вони є у Amazon, у Azure і т. Д. Load balancer на підставі власних правил вирішує, кому віддати виклик, якщо сервісів більше одного і неясно, де знаходиться сервіс.
Тут є ще один додатковий сервіс, service registry, Який кож буває різніх тіпів - в залежності від того, хто, як и де у него реєструється. Можна сделать так, щоб service registry реєстрував всі типи сервісів. Load balancer бере всі дані у service registry. Таким чином, завдання load balancer - просто брати дані про Місцезнаходження сервісів з service registry и розкідаті Предложения до них. А завдання service registry - зберігати реєстраційні дані сервісів, і він це робить по-різному: може опитувати сервіси сам, брати дані з зовнішнього конфіга і т. Д. Простір для маневрів тут бачиться дуже широким.
Client-Side Service Discovery
Client-Side Service Discovery - інший, радикально відрізняється спосіб взаємодії.
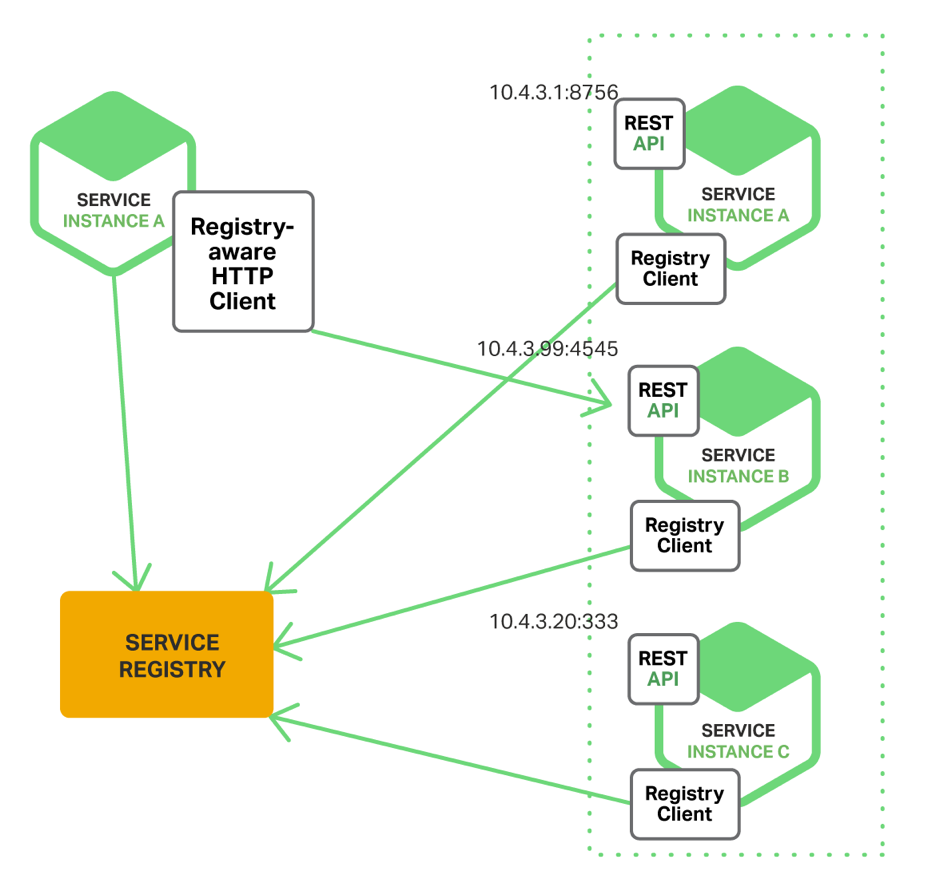
Тут немає load balancer, і сервіс звертається безпосередньо до service registry, звідки бере адресу сервісу. Чим це краще? Тим, що на один запит менше - так все працює швидше. Цей підхід кращий за попередній - але за умови, що у вас довірча система, в якій клієнт - внутрішній і не буде використовувати інформацію, яку приймає від сервісів, на шкоду (наприклад, для DDoS).
В цілому в Service Discovery все досить просто - використовуються досить відомі технології. Однак тут виникає складність - як реалізувати більш-менш серйозний бізнес-процес? Все одно сервіси при такому підході дуже сильно пов'язані, хоча проблему з точки зору розгортання і масштабування ми вирішуємо. Service instance A знає, що за даними потрібно йти до service instance B, а якщо завтра у вас зміниться половина додатки і функцію service instance B буде виконувати інший сервіс, вам доведеться багато переписувати.
Крім того, коли виникає транзакційна ситуація і потрібно узгодити дії декількох сервісів, знадобиться брокер (додатковий сервіс), який повинен все узгодити.
Message Bus
Message Bus потрібно вміти готувати і потрібно дійсно знати, що це таке. Message Bus використовується для цілком певних завдань, наприклад, не треба робити по Message Bus запити request-reply або передавати великі обсяги даних. Message Bus (і в принципі патерн Publish / Subscribe) розриває постачальників і споживачів інформації: постачальники не знають, кому потрібна інформація, а споживачі не знають, звідки вона береться - у однієї інформації теоретично можуть бути різні постачальники і споживачі.
І, як не старайся, в такій системі у вас повинен бути додатковий мережевий виклик - брокеру, який збирає повідомлення, і ще один виклик, коли ці повідомлення потрібно доставити. З мого досвіду, передавати великі обсяги даних (наприклад, мегабайти) через Message Bus не варто. Message Bus - шаблон командний; він потрібен, щоб один сервіс міг повідомити іншому, що у нього щось змінилося, щоб інші сервіси могли на це зреагувати.
У такій ситуації нам дуже допомогла б гібридна архітектура. Тоді ви берете і кидаєте по Message Bus повідомлення, що якісь дані помінялися. Після цього передплатники реагують на ці дані, йдуть в registry, забирають за ідентифікатором відправника місце, куди треба сходити за даними, і вже йдуть безпосередньо. Так ви дуже багато економите і розвантажите вашу шину.
Message Bus: «за» і «проти»
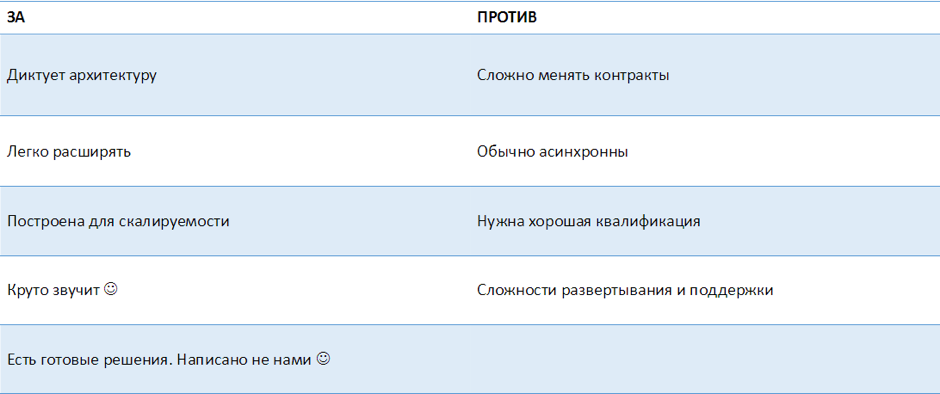
Переваги Message Bus:
- Message Bus визначає, яка у вас буде архітектура.
- Він дозволяє легко додавати сервіси, т. К. Одні сервіси не знають про інші.
- Message Bus спочатку побудований так, щоб всі системи скаліровалісь.
- Коли ви приходите до клієнта і говорите, що у вас буде ESB, - це просто круто звучить.
- Є готові рішення, які писали не ви, -такий код не треба підтримувати, і він добре працює.
Недоліки Message Bus:
- Т. к. Message Bus диктує архітектуру, він диктує і контракти: ви зобов'язані описувати message-контракти, які будете використовувати. Тому контракти міняти складно, їх потрібно версіоніровать. Можна використовувати різні механізми розширюваних контрактів на кшталт ProtoBuf, який дозволяє це робити зручно - розширені повідомлення читаються і попередніми версіями за рахунок зручного формату.
- Зазвичай асинхронні взаємодії. Щоб правильно з ними працювати,
- потрібно мати хорошу кваліфікацію.
- Ви додаєте ще один елемент в інфраструктуру розгортання - так з'являється ще одна зона ризику. Тут потрібні особливі знання у DevOps-інженера.
Event Driven Architecture - архітектура, керована подіями
Коли наші сервіси взаємодіють в стилі RPC, все зрозуміло: у нас є сервіс, який пов'язує всю бізнес-логіку, збирає дані з інших сервісів і повертає їх, але що робити в разі архітектури, керованої подіями? Ми не знаємо, куди йти, - у нас є тільки повідомлення.
В силу того, що сервіси працюють тільки зі своїми сховищами, у нас часто виникає ситуація, коли зміни в одному сервісі вимагають змін в іншому. Наприклад, у нас є якесь замовлення (order), і нам потрібно перевірити ліміти, що зберігаються в іншому сервісі (customer service):
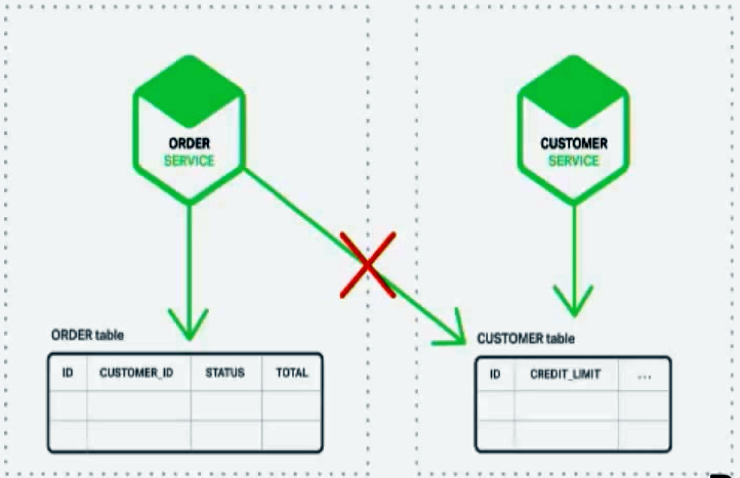
У цієї проблеми є два рішення.
рішення 1
Коли ви почнете процес створення замовлення, посилаєте в шину повідомлення про створення суті:
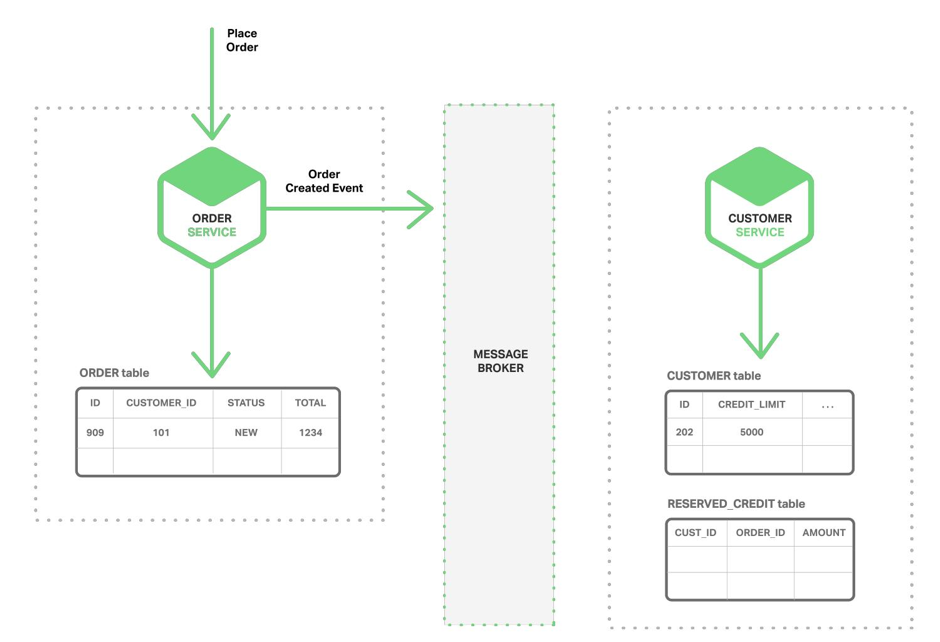
Сервіс, який зацікавлений в цих подіях, підписується на них і отримує ідентифікацію:
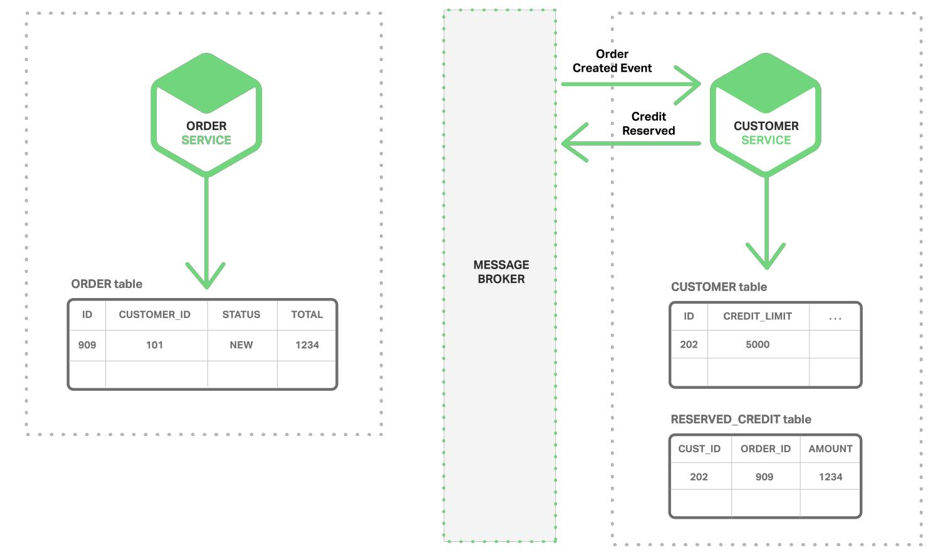
Потім він виконує якесь внутрішнє дію і повертає відповідь, який потім прилітає в сервіс замовлень, в шину:
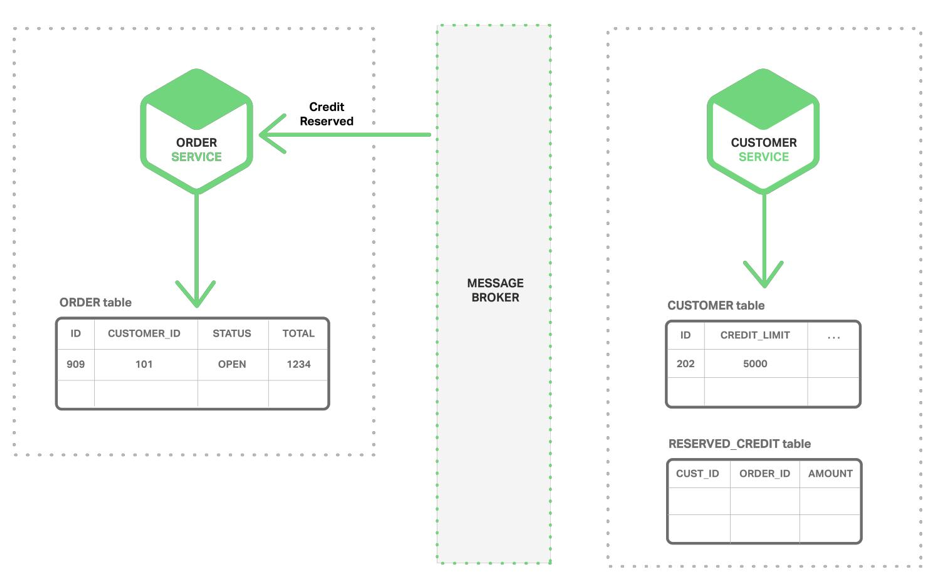
Все це називається кінцевої узгодженістю (eventual consistency). Відбувається це не атомарному, а за рахунок технології гарантованої доставки Message Bus. При цьому взаємодія сервісів з шиною - транзакційні, і шина забезпечує доставку всіх повідомлень. Тому ми можемо бути впевнені, що в кінці кінців до наших сервісів все долетить (якщо, звичайно, не вирішимо почистити повідомлення брокера через консоль адміністрування).
Якщо стандартна модель називається ACID, така транзакційна модель називається BASE - Basically Available, Soft state, Eventual consistency, що розшифровується приблизно так: стан, яке ви в підсумку отримуєте, називається "soft state", тому що ви не до кінця впевнені, що це стан дійсно актуально.
рішення 2
Є і другий спосіб. Може виявитися, що для прийняття рішень в цій системі вам не хочеться (або ви не можете в силу якихось вимог) кожен раз відправляти повідомлення в інший сервіс, адже час відгуку тут буде великим. У такій ситуації сервіс, який володіє якоюсь інформацією, - за кредитним лімітом, як в нашому прикладі, - в момент зміни кредитного ліміту оповіщає всіх зацікавлених, що інформація з даного клієнта змінилася. Сервіс, якому потрібно перевіряти кредитний ліміт, його перевіряє і зберігає собі проекцію потрібних даних, т. Е. Тільки ті поля, які йому потрібні. Звичайно, це буде дублікат даних, але дозволить сервісу нікуди не звертатися, коли буде замовлення.
Тут знову спрацьовує кінцева узгодженість: ви можете отримати замовлення, перевірити його кредитний ліміт і врахувати його як виконаний. Але т. К. В цей момент кредитний ліміт міг помінятися, може виявитися, що він не відповідає замовленням, і вам доведеться вибудовувати блоки компенсації - писати додатковий код, який буде реагувати на такі позаштатні ситуації. У цьому вся складність сервісних архітектур - потрібно заздалегідь розуміти, що дані, якими ви оперуєте, можуть виявитися застарілими, що може привести до неправильних дій.
Є ще й третій, дуже серйозний підхід - Event Sourcing. Це велика тема, яка потребує окремого обговорення. В Event Sourcing ви не зберігайте стану об'єктів - ви їх будуєте в реальному часі, а зберігайте тільки зміни об'єктів (фактично, наміри користувачів щось поміняти). Припустимо, відбувається щось в UI, наприклад, користувач хоче зробити замовлення. Тоді ви зберігаєте не зміна замовлення, не нове стан, а окремо зберігаєте зовнішні запити: від користувача, від інших сервісів і взагалі звідки завгодно. Навіщо це потрібно? Це потрібно для ситуації компенсації - тоді ви можете відкотити стан системи назад і діяти інакше.
Взагалі, Message Bus - дуже велика тема, в рамках якої дуже багато можна розповісти про узгодження подій. Наприклад, можна згадати Saga - маленький воркфлоу, який зараз реалізують, по крайней мере, NServiceBus і MassTransit. Saga - по суті, машина станів, яка реагує на зовнішні зміни, завдяки якій ви знаєте, що відбувається з системою. При цьому з будь-якого стану ви можете зробити блок компенсації. Т. ч. Saga - хороший інструмент реалізації кінцевої узгодженості.
Перехід від моноліту до мікросервісам
Тепер хочеться поговорити, як переходити від моноліту до мікросервісам, якщо ви вирішили, що це дійсно те, що потрібно. Отже, у вас є великий моноліт. Як тепер ділити його на частини?
Ви виймаєте щось, обмежене по бізнес-логіці (те, що називається обмеженим контекстом в DDD). Звичайно, для цього доведеться зрозуміти моноліт. Наприклад, хороший кандидат на виділення в окремий сервіс - частина моноліту, яка вимагає частих змін. Завдяки цьому, ви отримуєте оперативну вигоду від виділення сервса - не доведеться тестувати моноліт часто. Також добре виділяти в окремий сервіс те, що приносить найбільшу кількість проблем і погано працює.
Коли ви поділяєте моноліт на сервіси, звертайте увагу, як у вас структуровані команди. Адже є емпіричний закон Конвея (Conway's law), який говорить, що структура вашого застосування повторює структуру вашої організації. Якщо ваша організація побудована на технологічних ієрархіях, побудувати мікросервісную архітектуру буде дуже важко. Тому потрібно виділити feature-команди, які будуть мати всі необхідні навички, щоб написати потрібну логіку від початку до кінця.
Насправді, рідко буває, що у нас чиста мікросервісная архітектура. Найчастіше ми маємо щось середнє між монолітом і мікросервісамі. Зазвичай є якийсь великий історично сформований код, і ми потроху намагаємося розплутувати його і відокремлювати від нього частини.
Якщо ж ми робимо проект з нуля, потрібно вибрати - моноліт або мікросервіси?
Моноліт краще вибирати в наступних випадках:
- Якщо у вас новий домен і / або немає знань в цьому домені ..
- Якщо ви робите прототип або швидке рішення.
- Якщо команда не дуже кваліфікована (всі початківці, наприклад).
- Якщо вам потрібно просто написати код і забути про нього.
- Якщо мало грошей на проект - мікросервіси обійдуться дорого.
Мікросервіси краще вибрати, якщо:
- Точно знадобиться лінійне масштабування.
- Ви розумієте бізнес-домен, зможете виділити обмежений контекст і зможете забезпечити узгодженість на бізнес-рівні.
- Команда висококваліфікована, є досвід і пара загублених проектів з мікросервісамі в минулому (все одно з першого разу зробити мікросервіси не виходить).
- Має бути довгострокове співробітництво з замовником.
- Досить коштів для інвестування в інфраструктуру.
Мікросервіси: «за» і «проти»
переваги:
Мікросервісний підхід можна застосувати, навіть якщо ви не будете використовувати Message Bus, і мікросервіси будуть логічними. Адже, з точки зору розгортання, тут можливо різноманіття. Якщо говорити в термінах .NET, ви зможете розгортати сервіси навіть в рамках одного домена додатку. У вас будуть всього лише ізольовані модулі, які взаємодіють за допомогою обміну крізь пам'ять. Працюватиме дійсно швидко, при цьому не буде накладних мережевих витрат.
- Чітке модульне розподіл. Дозволить посилити модульну структуру - у вашій команді будуть люди, які прекрасно знають, як працює та чи інша частина коду. Це особливо важливо для великих команд розробників.
- Висока доступність. Сервіси можуть працювати не всі - при цьому все інше буде працювати.
- Різноманітність технологій, або можливість використовувати правильний інструмент. Наприклад, якщо потрібно побудувати сховище даних, ви підберете той інструмент, який дійсно вміє зберігати великі обсяги даних і швидко їх вибирати. Мікросервіси дозволяють навіть просто випробувати технологію на якомусь сервісі, і це не вплине на інші сервіси, т. К. Контракт ізольований через мережеву взаємодію.
- Незалежне розгортання через слабку зв'язаність сервісів: прості сервіси простіше розгортати, і менше ймовірність відмови системи.
недоліки:
- Складність розробки.
- Кінцева узгодженість - бізнес вашого замовника повинен дозволяти працювати з відкладеними даними. Цим доведеться платити за високу доступність. Класичний приклад кінцевої узгодженості - банківські карти, транзакції між якими можуть займати дня три. Через це є ймовірність перевищення кредитного ліміту, і тоді починає діяти найпростіший механізм компенсації - вам телефонують з банку з проханням погасити перевищення.
- Складність операційної підтримки - потрібні грамотні DevOps-інженери, безперервне розгортання і автоматичний моніторинг. Без всього цього мікросервіси використовувати не слід.
Трохи про моніторинг та тестуванні міроксервісной системи
Є інструменти, які дозволяють розгортати таку систему і стежити за нею, наприклад, ZooKeeper, який вирішує проблему конфігурації за нас. Також є такі інструменти типу Logstash, Kibana, Elastic, Serilog, Amazon Cloud Watch. Всі вони стежать за вашими сервісами.
Як тестувати мікросервісную систему? Я бачу це в такий спосіб. У вас є сервіс, який вирішує якусь бізнес-завдання. Ваша мета - протестувати його бізнес-контракти. Більшість тестів, які ви робите - модульні, які для коду, написаного в рамках цього сервісу. Це - низ піраміди тестування. Наступний рівень - інтеграційне тестування, яке перевіряє, як цей сервіс відповідає на стандартні запити. Тут у вас величезний простір для інтеграційного тестування коду, написаного ізольовано. Наступний етап - використання різних інструментів, щоб гарантувати, що договір не змінився. У нашому проекті ми використовували Swagger, який дозволяє зафіксувати контракт.
Маніфест Джеффа Безоса (Amazon CEO)
Наостанок приведу хороший приклад вкрай успішного застосування мікросервісной архітектури - Amazon.
Все почалося з того, що в 2000 р Джефф Безос, глава Amazon, написав для всіх відділів своєї компанії наступний маніфест:
- All teams will henceforth expose their data and functionality through service interfaces.
- Teams must communicate with each other through these interfaces.
- no direct linking
- no direct reads of another team's data store
- no shared-memory model
- no back-doors whatsoever.
- The only communication allowed is via service interface calls over the network.
- It does not matter what technology they use.
- All service interfaces, without exception, must be designed from the ground up to be externalizable.
- No exceptions.
Якщо коротко, суть маніфесту така: «Вся функціональність виставляється назовні тільки за допомогою інтерфейсів сервісів. Команди (насправді - сервіси та їх команди) взаємодіють тільки за допомогою мережевих інтерфейсів: ніякого взаємодії з базами даних, ніякої спільної пам'яті і т. Д. - незалежно від технологій і без винятків.
Таким чином, Джефф зобов'язав всі сервіси бути готовими, що їх виставлять в публічний доступ. Це призвело до рівня, коли можна пропонувати послугу як сервіс. Це стало запорукою успіху компанії. Ми знаємо, до чого в підсумку привів цей маніфест - до цілої індустрії Amazon і часткове виросла з цього індустрії AWS.
джерела
Як це зробити?За умови, що система розподілена, як забезпечити узгодженість даних?
І як при цьому ще й прискорити систему в N раз?
І тут у вас напевно виникне питання, як же SOA співвідноситься з мікросервісной архітектурою?
Що таке мікросервіси?
Однак тут часто виникає питання, чим висока узгодженість (high cohesion) відрізняється від SRP?
Як сервіси будуть один з одним взаємодіяти?
Чим це краще?
Однак тут виникає складність - як реалізувати більш-менш серйозний бізнес-процес?
Навіщо це потрібно?

