
Розробники часто готові представити час виконання якогось зручного запиту на створеної ними системи як результат, покликаний довести перевагу їх дітища над конкурентами, однак реальні показники можуть на порядки відрізнятися від результатів тестування.
У 2002 році було опубліковано близько 300 різних результатів оцінки СУБД, а в період з 2009 по 2012 рік спостерігався сплеск бенчмаркінгу по лінії TPC-C: кожен виробник СУБД і обладнання вважав справою честі відзвітувати про результати оцінки своїх продуктів. Однак у 2017 році на сайті Ради з оцінки продуктивності обробки транзакцій (Transaction Processing Performance Council, TPC.org) був опублікований лише один актуальний результат, і той - для вбудованої СУБД (SQL Anywhere). Багато в чому причиною охолодження інтересу стали змінилися типові навантаження для СУБД і нові моделі їх застосування, поява NoSQL і поширення нових уявлень про узгодженість даних. Але це лише часткове пояснення, для того щоб розібратися в обставинах, що склалися, треба не тільки проаналізувати нові бенчмарки, але і поглянути на проблему еталонного тестування СУБД в цілому.
початок
На зорі ери СУБД, на початку 1970-х років, в Bank of America, який налічував тоді 1 тис. Відділень і 10 тис. Операціоністів, задумалися освоїти централізовану безпаперову технологію, в зв'язку з чим виникла потреба в СУБД, здатної обробляти 100 транзакцій в секунду. Корпорація IBM у відповідь на цю потребу запропонувала інструментарій для перевірки цієї СУБД - тест TP1, що став першим в ряду метрик оцінки роботи баз даних. Він працював в пакетному режимі на стороні бази даних, не беручи до уваги ні мережу, ні час реакції оператора, а лише послідовно проводив операції зняття і зарахування коштів на клієнтський рахунок і видавав кількість транзакцій в секунду (tps).
Через десять років місткість ринку комерційних СУБД перевалила за мільярд доларів і творці систем стали спішно звітувати про видатні результати виконання TP1, повідомляючи про неймовірні 10 тис. Tps, хоча кінцеві замовники отримували максимум сотню транзакцій в секунду. Для наведення порядку в галузі доцент університету Вісконсіна Девід Девітт в 1982 році створив більш детермінований еталонний тест, з чіткими правилами масштабування, які не орієнтований на якусь предметну область, а працює з умовними кортежами. Однак покликаний покласти край бенчмаркінгового війнам тест лише розпалив їх сильніше: сталося так, що перша комерційна реляційна СУБД, що мала амбіції стати головною в світі транзакционной обробки, показувала на ньому дуже скромні результати. Закінчилося все скандалом - ходять чутки, що особисто Ларрі Еллісон дзвонив в Вісконсінський університет з вимогою звільнити ДеВітта, а отримавши відмову, заборонив кадровій службі Oracle наймати на роботу випускників цього вузу. Головним же підсумком для індустрії в цій історії стала так звана застереження ДеВітта, згідно з якою власникові ліцензії на СУБД забороняється публікувати будь б то не було результати тестів продуктивності без узгодження з виробником. Таку обмовку в текст ліцензійних угод включили постачальники практично всіх основних систем того часу. У більшості з них вона в тому чи іншому вигляді зберігається і донині.
На противагу абстрактному Вісконсінський тесту, корпорація Tandem в 1985 році вирішила повернути до життя рознічнобанковскій TP1, але вже з чіткою специфікацією і всіма обмеженнями, при яких було б неможливо розганяти tps. Так з'явився тест DebitCredit - результат роботи групи архітекторів Tandem, очолюваної Джимом Греєм [1]. У цьому тесті були задані базові стандарти еталонного тестування продуктивності СУБД: вперше чітко позначалося, що повинно розумітися під вартістю системи в цілому (в разі комерційної конфігурації вартість транзакції буде найбільш важливим показником); встановлювалися правила масштабування за кількістю користувачів з пропорційним зростанням розмірів таблиць; вводилося обмеження на час відгуку, згідно з яким 95% транзакцій має завершитися за одну секунду. Ці, здавалося б, очевидні уточнення тоді були в новинку, а сьогодні без такого роду обмежень не можна вважати осмисленим будь-який тест продуктивності, що імітує призначену для користувача навантаження.
Епоха TPC
Тест DebitCredit не відповідав на одне важливе питання: як переконатися в тому, що той чи інший результат можна порівняти з іншими? Нелегко було переконати грандів галузі слідувати вказівкам Tandem, тому вендори, підстібаються клієнтами з банківської сфери, де в той час почалося розгортання мережі банкоматів і від виробників були потрібні тисячі транзакцій в секунду, продовжували публікувати результати TP1. Потрібна була незалежна некомерційна організація, яка користувалася б авторитетом у всіх виробників, і в 1988 році була створена Рада з оцінки продуктивності обробки транзакцій. На момент перших зборів, на якому були затверджені специфікації тестів TPC-A і TPC-B, до Ради входило 26 компаній, включаючи всіх ключових виробників СУБД тих років: IBM, Informix, Oracle, Ingres, Sybase, DEC, Software AG, Teradata. Важливими складовими угоди стали прийняті методики розрахунку ціни, а також обов'язковість аудиту результатів в акредитованій організації.
Тести TPC-A і TPC-B відрізнялися тим, що в першому потрібні емуляція всього оточення (терміналів, мережі) і облік часу на реакцію користувача, а другий виконувався пакетно на стороні бази даних, та ще й з скороченою до 30 днів історією [2 ]. Простота реалізації TPC-B і донині приваблює розробників і консультантів. Наприклад, що входить в стандартну поставку PostgreSQL утиліта pgbench виконує TPC-B, і перші оцінки на знову розгортаються конфігураціях багато практикуючі фахівці роблять саме на TPC-B. У 1990 році був опублікований перший аудований результат TPC-A: одна з систем на платформі PA-RISC від Hewlett-Packard отримала 38,2 tpsA при 29,2 тис. Дол. За транзакцію в секунду. А через чотири роки з'явився останній, від компанії DEC, для сервера на платформі AlphaServer - 3700 tpsA з ціною на транзакцію в секунду в 4,7 тис. Дол. Але такий розкид результатів зовсім не свідчення прогресу, а лише ознака того, що до простого четирехтаблічному бенчмарку виявилося легко підлаштуватися. У 1995 році TPC-A і TPC-B були визнані неспроможними, і з'явився більш досконалий TPC-C.
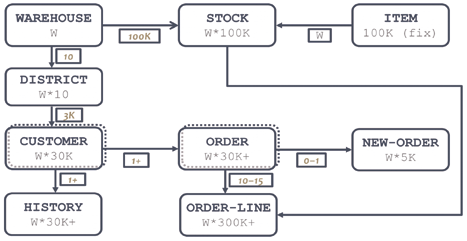
Мал. 1. Модель даних TPC-C
У TPC-C [2] була змінена предметна область, що відображало і експансію ринку транзакційних систем з банківської сфери на інші галузі - тепер в тесті потрібно імітувати роботу оптового складу (рис. 1). Квантом масштабування в бенчмарке вважається склад (W, WAREHOUSE), на кожному складі десять ділянок (DISTRICT), оснащених терміналом, кожен термінал призначений для реєстрації клієнтських замовлень (ORDER), що складаються із записів ORDER-LINE про одиниці зберігання (STOCK). Таких замовлень (транзакцій) кожну ділянку може провести не більше 1,2 в хвилину. Як тільки досягається гранична продуктивність в транзакціях в хвилину (tpmC), тест масштабується шляхом додавання ще одного складу, і поки 90% транзакцій відгукуються менш ніж за 5 с, масштабування триває. Крім введення нових замовлень (45% від загального навантаження) тест передбачає паралельне виконання та інших видів операцій: прийом платежу з оновленням балансу клієнта (43%), перевірку статусу останньої заявки від клієнта (4%), перевірку рівня запасів на складі (4% ), а також пакетний процес формування заявок на доставку (4%, до нього вимогу щодо порогу відгуку - 20 с).
За роки існування TPC-C в його специфікації були включені чіткі вимоги до надійності тестируемой конфігурації, що виключають можливість «оптимізацій», наприклад, за допомогою перенесення журналів упреждающей записи в оперативну пам'ять. З'явилася ще одна відносна метрика: W / ktpmC - споживання в ватах за кожну 1 тис. Транзакцій в хвилину зі складною методикою розрахунку енергоспоживання. Однак результатів з прорахованими ватами опубліковано було небагато. Результати TPC-C пропонувалися в двох номінаціях: некластерние і кластерної. Причому кластерними вважалися всі випадки, коли вузлів бази даних було більше одного, і не важливо, яким чином реалізовувалося це поділ.
До початку 2000-х років на сайті tpc.org накопичилася критична маса результатів: у інтеграторів та їх замовників був досить великий каталог конфігурацій комплектів з обладнання і СУБД з ретельно відміряними і перевіреними показниками продуктивності. Справа була лише за тим, як адаптувати синтетичні tpmC до реальної системи, і на цей рахунок з'явилися різні тлумачення. Найбільш показові «правила перерахунку» пропонував фахівець з налаштування СУБД на ОС Solaris Алан Паркер [3], який радив tpmC з результатів: ділити на два, якщо в цільовій системі паралельно активно формуються звіти або виконуються пакетні завдання; множити на 2/3, якщо використовуються легковагі екранні форми за типом написаних навколо бібліотеки curses, і на 1/3 - якщо форми типу Oracle Forms; ділити навпіл, якщо в системі не передбачений монітор транзакцій. На останнє правило варто звернути окрему увагу: специфікація TPC-C передбачає використання монітора транзакцій, що дозволяє природним чином будувати кластерні конфігурації, але ускладнює організацію тестування і свідомо здорожує систему на вартість ліцензій, які в разі Tuxedo або CICS досить недешеві.
Поряд із загальним визнанням TPC-C як еталону для OLTP-навантажень, поширилося і розуміння того, що мірки цього тесту нічого не скажуть про продуктивності OLAP-систем на відповідних конструкціях, та й поведінку реальних систем з великим числом оперативних звітів помітно відрізняється від заданого в специфікації. Назрілу необхідність в тестуванні СУБД для звітних навантажень намагалися втілити в тесті TPC-R, а відтворити поведінку OLAP-системи повинен був тест TPC-D, але обидва вийшли невдалими, і виробники не поспішали публікувати їх результати. Та ж доля спіткала і проіснував з 2001 по 2005 рік TPC-W, покликаний показувати продуктивність СУБД для умовного інтернет-магазину, - «тест для онлайн-веб-комерції», головна мета якого була, мабуть, в тому, що він випередив час.
У 1999 році вдалося створити визнається всіма тест для OLAP - TPC-H, в якому були усунені основні недоліки TPC-D: продумані методика масштабування і правила відліку тривалості виконання запитів; крім складних і довільних (ad-hoc) аналітичних запитів, передбачалося два паралельних ETL-потоку поновлення даних в сховищі. Було зроблено відступ від норми відмови специфицирования фрагментами коду, що дозволило деяким його частинах широко поширитися в вигляді окремо виконуваних SQL-запитів (багатьом розробникам добре відомий запит, що позначається Q1 - перший з специфікації). Однак відповідність такої специфікації практично нереально довести для тестів, зроблених на мові, відмінному від SQL. На відміну від транзакційних тестів, результати TPC-H залежать від «ваговій категорії», тому і позначаються відповідно: 10000 QphH @ 100GB означає виконання 10 тис. Запитів на годину на базі в 100 Гбайт. Станом на 2017 рік є результати майже у всіх «вагових категоріях»: 100 Гбайт, 300 Гбайт, 1 Тбайт, 3 Тбайт, 10 Тбайт, 30 Тбайт, 100 Тбайт для СУБД Actian Vector, Exasol, Oracle Database і Microsoft SQL Server.
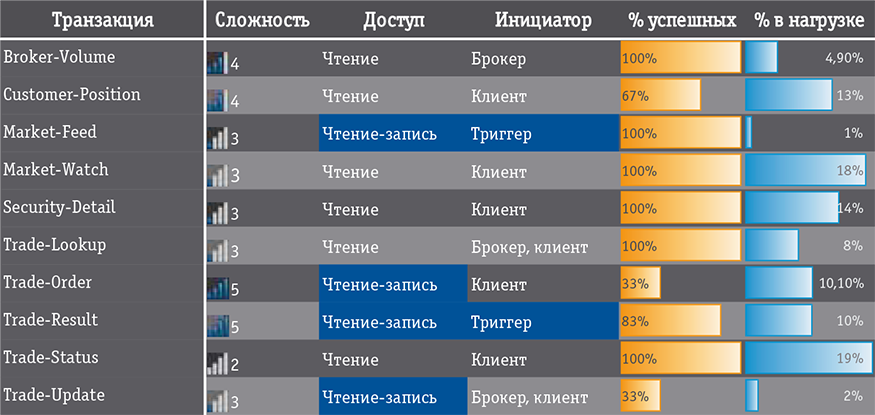
Мал. 2. Потоки TPC-E
У 2006 році була опублікована специфікація транзакційного тесту нового покоління - TPC-E, в яку увійшли декларативні обмеження цілісності (в ранні транзакційні тести їх не включали - в СУБД зразка 1990-х років не все було добре з гранулярністю блокувань); були скасовані монітори транзакцій; операцій на вибірку передбачалося значно більше; пропонувалося також виконувати більше неуспішних операцій (рис. 2). Відповідно до сподіваннями ринку знову була змінена предметна область: TPC-E має відтворювати діяльність брокерського будинку, а модель даних описувалася трьома десятками таблиць. Виробники, однак, публікувати результати не поспішали, і хоча до 2017 року на сайті зібралося 78 результатів, у всіх них тестувалася тільки система Microsoft SQL Server в некластерние конфігурації на Windows x64. Проте 78 результатів - це більше, ніж один у TPC-C, і висновок про кінець TPC-C і передачі естафети TPC-E напрошується сам собою: без сумніву, що поряд з -A / B, -C, -H він закріпився серед практичних бенчмарков (рис. 3).
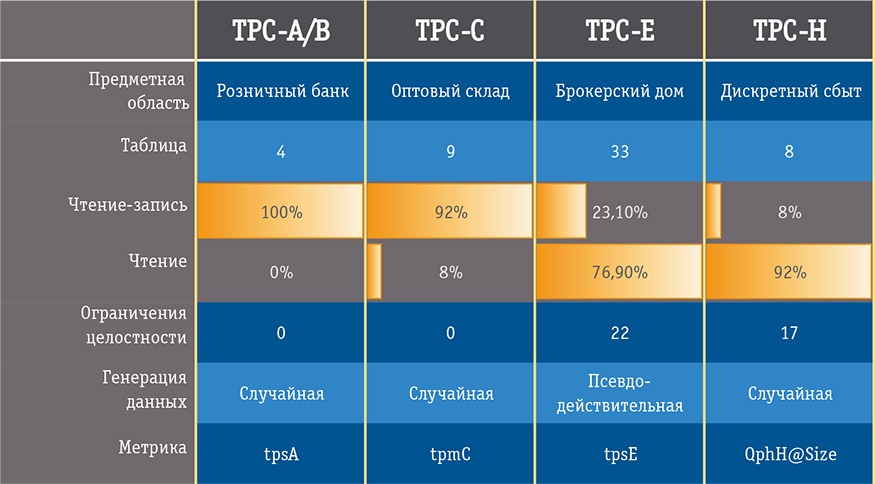
Мал. 3. Основні тести TPC
Нові Навантаження - Нові тести
У 2008 році у всесвітню інформаційно-технологічну історію увірвався Hadoop, чому значною мірою сприяли результати тестування від Yahoo !: сортування одного терабайта даних на кластері з 910 вузлів зайняла 210 секунд. Цей тест, який отримав назву TeraSort, бере початок з уже згаданого звіту Tandem, де він називався AlphaSort. Для прогону TeraSort не потрібно так само ретельно вибудовувати оточення, як для тестів TPC, - генерація тестового набору, запуск бенчмарка і перевірка результату вимагають по одній командному рядку, а пакетний характер тесту не накладає обмежень на результат (як тільки сортування заданого обсягу завершена, можна зупиняти таймер). Незабаром з'явилися і інші бенчмарки для Hadoop, пов'язані з типами навантажень, цікавими для пакетної масово-паралельної обробки. Всі найважливіші з них акуратно упаковані корпорацією Intel в інструментарій HiBench, до якого включено: PageRank - ранжирування посилань за алгоритмом від Google; Nutch Indexing - індексація текстів; оцінки для задач машинного навчання - байєсівську класифікація та кластеризація методом K-середніх. Але саме TeraSort став фактичним стандартом для масово-паралельних систем обробки даних, який породив нову категорію тестів в TPC - серію експрес-бенчмарков, що позначаються TPCx-, для акцентування на простоті відтворення результатів, що зближує їх в цьому сенсі з тестами SPEC. Так народився тест TPCx-HS, в якому не обов'язково сортувати рівно 1 Тбайт - слідуючи логіці TPC-H, передбачені й інші «вагові категорії»: від 1 до 5 Тбайт, 10, 30, 100 і 300 Тбайт. Швидше за все, цей бенчмарк вже отримав путівку в життя.
Складніші справи з TPC-DS і створеним на його основі тестом BigBench, зареєстрованим як експрес-бенчмарк TPCx-BB, - по ним поки немає жодного результату. TPC-DS запропонований як альтернатива TPC-H з відв'язку від реляційної специфіки, і Радою він описаний як «запускається на системах великих даних, таких як реляційні СУБД і системи на основі Hadoop / Spark». Провести тестування з BigBench не складніше, ніж TeraSort, і регулярно з'являються повідомлення про його запусках в тих чи інших конфігураціях (Hive над Spark, Hive над Tez), тому, схоже, у нього багато шансів на популяризацію.
Різноманітність сучасних затребуваних навантажень настільки велике, що саме уявлення про межі застосування СУБД в свідомості практиків істотно розширилося. Обробка геопросторових даних, мультимедіа, XML, JSON - все це навантаження для СУБД в широкому сенсі, і для кожної з них потрібен свій еталонний тест. І навіть не заглиблюючись в інші структури, ми бачимо, що транзакційні навантаження сучасності виявляються кардинально різними. Це добре відображає цікава колекція різноманітних бенчмарков в інструменті OLTPBench, який працює з будь-якої реляційної СУБД, що підтримує JDBC. Крім класики у вигляді TPC-C, в OLTPBench є типові навантаження, зняті з баз даних Twitter, Wikipedia, Epinions.com, а також суміш TPC-C і TPC-H під назвою benCHmark, повний комплект навантажень YCSB (Yahoo! Cloud Services Benchmark ) і Графова тест LinkBench.
LinkBench, що відтворює навантаження соціальної мережі Facebook, спочатку був покликаний відповісти на питання вибору платформи зберігання для цього мегасайта: залишатися на MySQL або переходити на HBase. І хоча трехтаблічная модель даних нетипова для інформаційних систем в класичному розумінні, але раз вона виявилася ефективною в настільки великій інтернет-компанії і поведінку СУБД на ній істотно відрізняється від класичних предметних моделей, то бенчмарк не може не викликати інтересу. До того ж підкуповує його методологічна опрацювання: використання законів статистики при генерації даних, відлік середнього відгуку в 99-м перцентилей, відсічення викидів, а ще й те, що тест виявився придатним для порівняння систем з абсолютно різних класів. Співробітники Facebook в результаті зробили вибір на користь MySQL, пізніше ж інструмент був адаптований для документоорієнтованих MongoDB, графовой OrientDB і реляційної PostgreSQL.
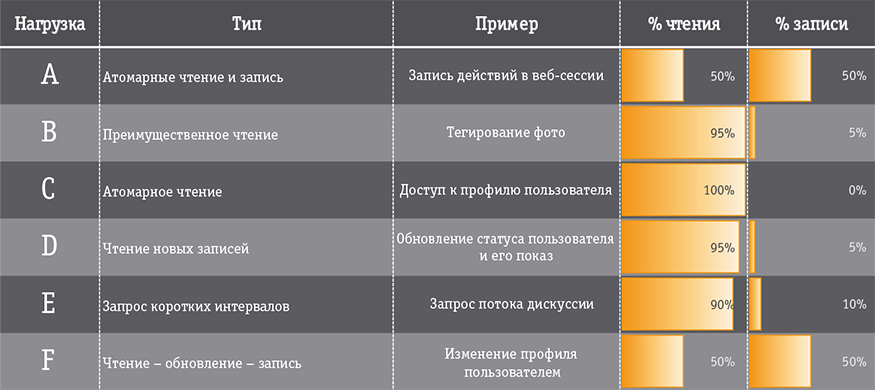
Мал. 4. Комплект навантажень Yahoo! Cloud Services Benchmark
Популярність YCSB такоже пов'язана з его застосовність до ОЦІНКИ СУБД різноманітніх класів, но з простотою інтерпретації результатів справа идет складніше - це не один тест, а Шість (рис. 4), причому КОЖЕН вірішує свою спеціфічну завдання, а не орієнтований на суміш НАВАНТАЖЕННЯ . Всі операции в усіх тестах атомарний (один запису - одна транзакція, максимум - читання декількох запісів), а НАВАНТАЖЕННЯ подається пакетно в API-режімі. Легкість виконання тесту зробила YCSB чи не запускаються бенчмарком сучасності, з його допомогою примудрялися порівняти десяток СУБД з різних класів: Cassandra, Elastic Search, Tarantool, OrientDB і ін. [4]. Однак якийсь глибинний сенс в отриманих результатах знайти важко, та й можливості підстроювання для таких тестів при відсутності регламентування надійності та відмовостійкості вимагають їх результати сприймати з обережністю.
При всій нагальність завдання побудови для нових категорій СУБД нових еталонних тестів, що забезпечують порівнянність в своєму класі, ініціативні спроби їх створення без глибокого опрацювання специфікації часто призводять до сутичок виробників, як це вже було за часів TP1. Показовим є приклад недавнього конфлікту між Gridgain і Hazelcast - представниками світу резидентних грід даних (нині сприймаються не тільки як сполучна ПО, але і як самостійні СУБД): один з виробників створив своєрідний бенчмарк з промовистою назвою Yardstick і оцінив результати порівняння з конкуруючої системою в свою користь , що було оскаржене іншою стороною з доказом вже власного переваги в точності на тому ж тесті.
«Кишенькові» кошти
Проблема самостійної оцінки продуктивності СУБД, особливо в умовах малої кількості надійних і перевірених результатів на TPC.org, до сих пір актуальна для практиків. З одного боку, з'являються упаковані в зручні інструменти нові тести, надійність одержуваних результатів для яких, однак, не очевидна. З іншого боку, є зручні графічні інструменти, які виконують серію тестів TPC, такі як HammerDB або Quest Benchmark Factory for Databases. Але і їх результати не можна вважати порівнянними з опублікованими на сайті Ради, хоча б в силу того, що TPC-C працює в них без моніторів транзакцій, запуск проводиться з одного навантажувальної станції, а вже про можливості пред'явити ці результати для аудиту навіть говорити не доводиться . Але можна і трохи заступитися за HammerDB: на сайті цього популярного інструменту створена громадська обмінник результатами, а раз вони все робляться в рамках одного інструмента, то їх можна вважати порівнянними і в цьому сенсі цінними. Є реалізації тестів TPC, створювані силами ентузіастів (tpcemysql від Percona і комплект тестів OSDBLT з osdblt.sourceforge.net), але досвід їх складання і використання суперечливий.
Наслідком складнощів відтворення великих і «правильних» бенчмарков стало зміщення уваги фахівців на прості інструменти, які «знімають» прості показники, але роблять це досить надійним чином - так, що забезпечується повторюваність результатів. Наприклад, в спільнотах користувачів MySQL стандартним став інструмент Sysbench, вираховує показники введення-виведення, роботи з потоками і семафора, завантаження процесора, а також своєрідну метрику, названу oltp. Користувачі Oracle Database використовують ряд вбудованих і зовнішніх інструментів для вимірювання продуктивності процесора, пам'яті, підсистеми введення-виведення на умовно-максимальних навантаженнях, серед яких найповніший інструмент - Peakmarks Benchware.
атомізація метрик
А чим сьогодні можуть похвалитися виробники машин баз даних - предконфігурірованних апаратно-програмних комплексів з ретельно откалиброванной і готової до промислових навантажень СУБД? Лише компанія Teradata ще в 2003 році останній раз публікувала результати тестів TPC-H, але при цьому її машини поставляються з вбудованим інструментом виміру деякого «внутрішнього QphH», що позначається як tPerf. В машинах Pure Data for Operational Analytics від IBM серед «паспортних показників» можна зустріти кількість операцій введення-виведення (IOPS) на SQL-навантаженні, пропускну здатність на SQL-навантаженні, швидкість завантаження даних в терабайт на годину. Схожі показники публікуються в «паспорті» на машини Exadata від Oracle - їх флагманський комплекс X6-8 прагне вразити потенційного клієнта небувалими 4,13 млн SQL IOPS і пропускною спроможністю 350 Гбайт / с на SQL-навантаженні. Як перевірити ці показники декількома різними способами для Oracle Database, знає будь-який адміністратор: є вбудований PL / SQL-пакет від Oracle, є Benchware, а такі інструменти, як Orion і SLOB, дозволяють прикинути майбутній SQL IOPS на системі зберігання без установки СУБД.
Виникає питання: якщо ключові виробники комплексів з СУБД вважають такі атомарні показники, як IOPS, інформативними і якщо їх можна отримати відносно зрозумілим шляхом, то чому б не глянути на них пильніше? Дійсно, в умовах добре утилизируемой процесорної потужності та високого паралелізму кількість IOPS, які здатна забезпечити СУБД, виявляється самим критичним показником для транзакционной навантаження і має корелювати з tpm і tps (за умови досить низького часу відгуку на максимальних навантаженнях). Для аналітичної навантаження, для якої важливо не стільки кількість операцій (розміри блоків в таких базах даних, як правило, роблять великими), скільки обсяги «прокачувати» гігабайтів, «пропускна здатність на SQL-навантаженні» виявляється часто більш показовою, ніж число незрозуміло яких запитів на годину. Однак ця теза вразливий: робота з підсистемою зберігання в різних СУБД реалізована принципово по-різному (та й не всі СУБД оснащені власним менеджером томів і працюють безпосередньо з блочними пристроями), тому одне і те ж число SQL IOPS для різних СУБД буде означати різну кількість транзакцій в хвилину. Крім того, різні СУБД по-різному працюють і з підключеннями, що також важливо. Багато питань виникає і до стандартизації інструментарію: якщо зрозуміло, як вимірювати IOPS для Oracle Database, IBM DB2 і Microsoft SQL Server, то для більшості інших СУБД готових інструментів немає. Але, як би там не було, підхід заслуговує на увагу хоча б в силу того, що він потенційно універсальний, а його полюси - IOPS і пропускна здатність - дозволяють оцінити якість виконання навантажень двох великих протиборчих категорій: часто записуються невеликі порції даних і читання великих обсягів з аналітичною обробкою.
***
Пропонуючи придивитися до атомарним показниками введення-виведення на специфічній для обробки даних навантаженні, хочеться також висловити надію на повернення до життя тестів TPC - надзвичайно важко буде знову зібрати настільки ж авторитетну організацію, що забезпечує методичну чистоту тестів і беззаперечну надійність опублікованих результатів. Є також надія на те, що проблема складності роботи з тестами переборна і серед результатів tpc.org ми ще побачимо дані за відкритими СУБД. Адже кому, як не їм, конкурувати за вартістю транзакції з комерційними?
За рамками розгляду залишилися специфічні для тиражованих додатків еталонні тести, такі як SAPS (на модулі SAP SD), SAP BW-EML, стандартні бенчмарки Oracle e-Business Suite, тести для Microsoft Dynamics AX. Результати їх виконання іноді публікуються, проте їх застосовність обмежується самими цими системами без урахування розширень (та й СУБД в цих змінах не обов'язково є вузьким місцем). Проте сам підхід, коли в основу еталонного тесту лягає реальне навантаження від реального додатки, перспективний, і популярність графового Linkbench тому свідчення.
Ще однією примітною тенденцією в умовах великих горизонтально масштабованих систем стає акцент в тестуванні не стільки на продуктивності, скільки на коректності функціонування. Яскравий представник тестів нового покоління - Jepsen, яким були продемонстровані втрати даних в кластерах під керуванням MongoDB, Redis і RethinkDB. Важливо, що сам автор цих тестів наполягає на тому, що не варто їх застосовувати для оцінки продуктивності (хоча метричні показники в них знімаються) і що це тільки «перевірка на злам». Але оскільки і продуктивність має сенс порівнювати лише в однакових «класах разрушімості», то опрацювання такого роду перевірок на коректність функціонування стає найважливішим напрямком у справі побудови еталонного тесту для сучасних СУБД.
Нарешті, хотілося б ще раз звернути увагу на нетривіальність проблеми еталонного тестування СУБД в цілому. Незалежного консультанта слід пам'ятати про пройдений галуззю шляху з вироблення надійних і загальноприйнятих еталонних тестів, щоб не стикатися з ситуаціями, коли реальні показники на порядки відрізняються від результатів тестування.
література
1. Леонід Черняк. Знову про тести TPC // Відкриті Сістеми.СУБД. - 2000. - № 11. - С. 34-36. URL: https: //www.osp. ru / os / 2000/11/178309 (дата звернення: 18.05.2017).
2. А.А. Волков. Тести TPC // СУБД.- 1995. - № 2. С. 70-78. URL: https: // www. osp.ru/dbms/archive/1995/02 (дата звернення: 18.05.2017).
3. Alan Parker. Tuning Databases on Solaris Platform. NJ: Prentice Hall, 2001., ISBN: 0130834173.
4. V. Abramova, J. Bernardino, P. Furtado. Experimental Evaluation of NoSQL Databases // International Journal of Database Management Systems (IJDMS). - 2014. Vol. 6, No. 3 (June). DOI: 10.5121 / ijdms.2014.6301.
Стаття Андрій Ніколаєнко, «Еталонні тести СУБД: що було, що стало, що буде» Републіка з дозволу видавництва «Відкриті системи» ( www.osp.ru ). Всі права збережені.
Автор: Андрій Ніколаєнко
Поділитися:
Адже кому, як не їм, конкурувати за вартістю транзакції з комерційними?
